
Introducing 'kafka-streams-cassandra-state-store'
The Java library to be introduced - thriving-dev/kafka-streams-cassandra-state-store - is a Kafka Streams State Store implementation that persists data to Apache Cassandra.
It's a 'drop-in' replacement for the official Kafka Streams state store solutions, notably RocksDB (default) and InMemory.
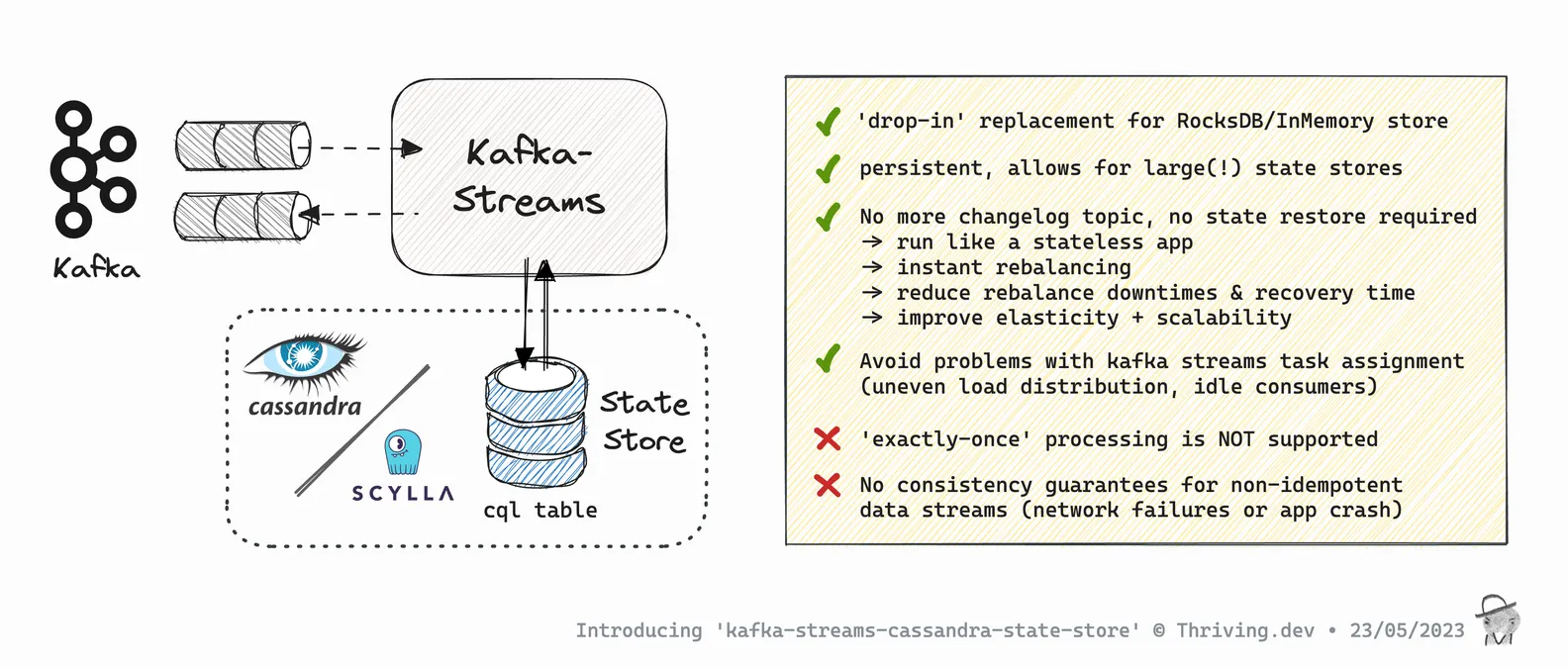
By moving the state to an external datastore the stateful streams app (from a deployment point of view) effectively becomes stateless - which greatly improves elasticity, reduces rebalancing downtimes & failure recovery.
Cassandra/ScyllaDB is horizontally scalable and allows for huge amounts of data which provides a boost to your existing Kafka Streams application with very little change to your existing source code.
In addition to the CassandraKeyValueStore this post will also cover all out-of-the-box state store solutions, explain individual characteristics, benefits, drawbacks, and limitations in detail.
Following the introduction and getting started guide, there's also a demo available.
If you don't want to wait, feel free to head over to the Thriving.dev YouTube Channel.
The first public release was on 9 January 2023.
When writing this blog post the latest version was:0.4.0- available on Maven Central!
Basics Recap
(Feel free to skip straight to the next section if you're already familiar with Kafka Streams and Apache Cassandra…)
Kafka Streams
Quoting Apache Kafka - Wikipedia:
“Kafka Streams (or Streams API) is a stream-processing library written in Java. It was added in the Kafka 0.10.0.0 release. The library allows for the development of stateful stream-processing applications that are scalable, elastic, and fully fault-tolerant. The main API is a stream-processing domain-specific language (DSL) that offers high-level operators like filter, map, grouping, windowing, aggregation, joins, and the notion of tables. Additionally, the Processor API can be used to implement custom operators for a more low-level development approach. The DSL and Processor API can be mixed, too. For stateful stream processing, Kafka Streams uses RocksDB to maintain local operator state. Because RocksDB can write to disk, the maintained state can be larger than available main memory. For fault-tolerance, all updates to local state stores are also written into a topic in the Kafka cluster. This allows recreating state by reading those topics and feed all data into RocksDB.”
In case you are entirely new to Kafka Streams, I recommend to get started with reading some official materials provided by Confluent, e.g. Introduction Kafka Streams API
Apache Cassandra
Quoting Apache Cassandra - Wikipedia:
“Apache Cassandra is a free and open-source, distributed, wide-column store, NoSQL database management system designed to handle large amounts of data across many commodity servers, providing high availability with no single point of failure. Cassandra offers support for clusters spanning multiple datacenters, with asynchronous masterless replication allowing low latency operations for all clients.”
Purpose
While Wikipedia’s summary (see above) only mentions RocksDB, Kafka Streams ships with following KeyValueStore implementations:
org.apache.kafka.streams.state.internals.RocksDBStoreorg.apache.kafka.streams.state.internals.InMemoryKeyValueStoreorg.apache.kafka.streams.state.internals.MemoryLRUCache
Let’s look at the traits of each store implementation in more detail…
RocksDBStore
RocksDB is the default state store for Kafka Streams.
The RocksDBStore is a persistent key-value store based on RocksDB (surprise!). State is flushed to disk, allowing the state to exceed the size of available memory.
Since the state is persisted to disk, it can be re-used and does not need to be restored (changelog topic replay) when the application instance comes up after a restart (e.g. following an upgrade, instance migration, or failure).
The RocksDB state store provides good performance and is well configured out of the box, but might need to be tuned for certain use cases (which is no small feat and requires an understanding of RocksDB configuration). Writing to and reading from disk comes with I/O, for performance reasons buffering and caching patterns are in place. The record cache (on heap) is particularly useful for optimising writes by reducing the number of updates to local state and changelog topics. The RocksDB block cache (off heap) optimises reads.
In a typical modern setup stateful Kafka Streams applications run on Kubernetes as a StatefulSet with persistent state stores (RocksDB) on PersistentVolumes.
InMemoryKeyValueStore
The InMemoryKeyValueStore, as the name suggests, maintains state in-memory (RAM).
One obvious benefit is that the pure in-memory stores come with good performance (operates in RAM…). Further, hosting and operating are simpler compared to RocksDB, since there is no requirement to provide and manage disks.
Drawbacks to having the store in-memory are limitations in store size and increased infrastructure costs (RAM is more expensive than disk storage). Further, state always is lost on application restart and therefore first needs to be restored from changelog topics (recovery takes longer).
When low rebalance downtimes / quick recovery is concerned, using standby replicas (num.standby.replicas) help to reduce recovery time.
MemoryLRUCache (Stores.lruMap)
The MemoryLRUCache is an in-memory store based on HashMap. The term cache comes from the LRU (least recently used) behaviour combined with the maxCacheSize cap (per streams task!).
It’s a rather uncommon choice but can be a valid fit for certain use cases. Same as the InMemoryKeyValueStore state always is lost on application restart and is restored from changelog topics.
maxCacheSize applies client-side only (in-memory HashMap, per streams task state store -> the least recently used entry is dropped when the underlying HashMap’s capacity is breached) but does not ‘cleanup’ the changelog topic (send tombstones). The (compacted) changelog topic keeps growing in size while the state available to processing is constrained by maxCacheSize.
Therefore, it is recommended to use in combination with custom changelog topic config cleanup.policy=[compact,delete] (also retention.ms) to have a time-based retention in place that satisfies your functional data requirements (if possible).
The maxCacheSize is applied per streams task (~input topic partitions), so take into consideration when calculating total capacity, memory requirements per app instance, …
CassandraKeyValueStore
Now finally we get to the subject of this blog post, the custom implementation of a state store that persists data to Apache Cassandra.
With CassandraKeyValueStore data is persistently stored in an external database -> Apache Cassandra <- *or compatible solutions (e.g. ScyllaDB). Apache Cassandra is a distributed, clustered data store that allows to scale horizontally to enable up to Petabytes of data, thus very large Kafka Streams state can be accommodated.
Moving the state into an external data store - outside the application so to say - allows you to effectively run the app in a stateless fashion. Further, with logging disabled, there's no changelog topic -> no state restore required which enables fluent rebalancing and helps reduce rebalance downtimes and recovery time.
This greatly improves the elasticity and scalability of your application, which opens up more possibilities such as e.g. efficient & fluent autoscaling...
It can also help ease/avoid known problems with the 'Kafka Streams'-specific task assignment such as 'uneven load distribution' and 'idle consumers' (I'm thinking about writing a separate blog post on these issues...).
Kafka Streams property internal.leave.group.on.close=true allows to achieve low rebalance downtimes by telling the consumers to send a LeaveGroup request to the group leader on graceful shutdown.
For more information on such kafka internals I can recommend to watch+read following Confluent developer guide: Consumer Group Protocol.
Note that this property is also used & explained in the demo.
⚠ Please be aware this is an in-official property (not part of the public API), thus can be deprecated or dropped any time.
Adding an external, 3rd party Software to the heart (or rather stomach?) to your stream processing application, adds a new, additional single point of failure to your architecture.
Usage Example
Get it!
The artifact is available on Maven Central:
Maven
<dependency>
<groupId>dev.thriving.oss</groupId>
<artifactId>kafka-streams-cassandra-state-store</artifactId>
<version>${version}</version>
</dependency>
Gradle (Groovy DSL)
implementation 'dev.thriving.oss:kafka-streams-cassandra-state-store:${version}’
Classes of this library are in the package dev.thriving.oss.kafka.streams.cassandra.state.store.
Quick Start
High-level DSL <> StoreSupplier
When using the high-level DSL, i.e., StreamsBuilder, users create StoreSuppliers that can be further customized via Materialized.
For example, a topic read as KTable can be materialized into a Cassandra k/v store with custom key/value Serdes, with logging and caching disabled:
StreamsBuilder builder = new StreamsBuilder();
KTable<Long,String> table = builder.table(
"topicName",
Materialized.<Long,String>as(
CassandraStores.builder(session, "store-name")
.keyValueStore()
)
.withKeySerde(Serdes.Long())
.withValueSerde(Serdes.String())
.withLoggingDisabled()
.withCachingDisabled());
Processor API <> StoreBuilder
When using the Processor API, i.e., Topology, users create StoreBuilders that can be attached to Processors.
For example, you can create a Cassandra KeyValueStore<String, Long> with custom Serdes, logging and caching disabled like:
Topology topology = new Topology();
StoreBuilder<KeyValueStore<String, Long>> storeBuilder = Stores.keyValueStoreBuilder(
CassandraStores.builder(session, "store-name")
.keyValueStore(),
Serdes.String(),
Serdes.Long())
.withLoggingDisabled()
.withCachingDisabled();
topology.addStateStore(storeBuilder);
Demo
Features the notorious 'word-count example' (ref), written as a quarkus application, running in a fully clustered docker-compose localstack.
Source code for this demo: kafka-streams-cassandra-state-store/examples/word-count-quarkus (at 0.4.0)
Store Types
kafka-streams-cassandra-state-store comes with 2 different store types:
- keyValueStore
- globalKeyValueStore
keyValueStore (recommended default)
A persistent KeyValueStore<Bytes, byte[]>.
The underlying cassandra table is partitioned by the store context task partition.
Therefore, all CRUD operations against this store always query by and return results for a single stream task.
globalKeyValueStore
A persistent KeyValueStore<Bytes, byte[]>.
The underlying cassandra table uses the record key as sole /PRIMARY KEY/.
Therefore, all CRUD operations against this store work from any streams task and therefore always are “global”.
Due to the nature of cassandra tables having a single PK (no clustering key), this store supports only a limited number of operations.
If you're planning to use this store type, please make sure to get a full understanding of the specifics by reading the relevant docs to understand its behaviour.
Advanced
For more detailed documentation, please visit the GitHub project…
Under the hood
Implemented/compiled with
- Java 17
- kafka-streams 3.4
- datastax java-driver-core 4.15.0
Supported client-libs
- Kafka Streams 2.7.0+ (maybe even earlier versions, but wasn’t tested further back)
- Datastax java client (v4)
'com.datastax.oss:java-driver-core:4.15.0' - ScyllaDB shard-aware datastax java client (v4) fork
'com.scylladb:java-driver-core:4.14.1.0'
Supported databases
- Apache Cassandra 3.11
- Apache Cassandra 4.0, 4.1
- ScyllaDB (should work from 4.3+)
Underlying CQL Schema
keyValueStore
Using defaults, for a state store named "word-count" the following CQL Schema applies:
CREATE TABLE IF NOT EXISTS word_count_kstreams_store (
partition int,
key blob,
time timestamp,
value blob,
PRIMARY KEY ((partition), key)
) WITH compaction = { 'class' : 'LeveledCompactionStrategy' }
globalKeyValueStore
Using defaults, for a state store named "clicks-global" the following CQL Schema applies:
CREATE TABLE IF NOT EXISTS clicks_global_kstreams_store (
key blob,
time timestamp,
value blob,
PRIMARY KEY (key)
) WITH compaction = { 'class' : 'LeveledCompactionStrategy' }
Feat: Cassandra table with default TTL
Cassandra has a table option default_time_to_live (default expiration time (“TTL”) in seconds for a table) which can be useful for certain use cases where data (state) expires after a known period.
Please note writes to Cassandra are made with system time. The table TTL is applied based on 'time of write' -> the time of the current record being processed (!= stream time).
The default_time_to_live can be defined via the builder withTableOptions method, e.g.:
CassandraStores.builder(session, "word-grouped-count")
.withTableOptions("""
compaction = { 'class' : 'LeveledCompactionStrategy' }
AND default_time_to_live = 86400
""")
.keyValueStore()
Cassandra table partitioning (avoiding large partitions)
Kafka is persisting data in segments and is built for sequential r/w. As long as there’s sufficient disk storage space available to brokers, a high number of messages for a single topic partition is not a problem.
Apache Cassandra on the other hand can get inefficient (up to severe failures such as load shedding, dropped messages, and crashed and downed nodes) when the partition size grows too large. The reason is that searching becomes too slow as the search within a partition is slow. Also, it puts a lot of pressure on the (JVM) heap.
The community has offered a standard recommendation for Cassandra users to keep Partitions under 400MB, and preferably under 100MB.
For the current implementation, the Cassandra table created for the ‘default’ key-value store is partitioned by the Kafka partition key (“wide partition pattern”).
Please keep these issues in mind when working with relevant data volumes.
In case you don’t need to query your store / only lookup by key (‘range’, ‘prefixScan’; ref Supported operations by store type) it’s recommended to use globalKeyValueStore rather than keyValueStore since it is partitioned by the event key (:= primary key).
- blog post on Wide Partitions in Apache Cassandra 3.11
Note: in case anyone has funded knowledge if/how this has changed with Cassandra 4, please share in the comments below!! - stackoverflow question
Known Limitations
Adding additional infrastructure for data persistence external to Kafka comes with certain risks and constraints.
Consistency
Kafka Streams supports at-least-once and exactly-once processing guarantees. At-least-once semantics is enabled by default.
Kafka Streams exactly-once processing guarantees is using Kafka transactions. These transactions wrap the entirety of processing a message throughout your streams topology, including messages published to outbound topic(s), changelog topic(s), and consumer offsets topic(s).
This is possible through transactional interaction with a single distributed system (Apache Kafka). Bringing an external system (Cassandra) into play breaks this pattern. Once data is written to the database it can’t be rolled back in the event of a subsequent error / failure to complete the current message processing.
=> If you need strong consistency, have exactly-once processing enabled (streams config: processing.guarantee="exactly_once_v2"), and/or your processing logic is not fully idempotent then using kafka-streams-cassandra-state-store is discouraged!
ℹ️ Please note this is also the case when using kafka-streams with the native state stores (RocksDB/InMemory) with at-least-once processing.guarantee (default).
For more information on Kafka Streams processing guarantees, check the sources referenced below.
- https://medium.com/lydtech-consulting/kafka-streams-transactions-exactly-once-messaging-82194b50900a
- https://docs.confluent.io/platform/current/streams/developer-guide/config-streams.html#processing-guarantee
- https://docs.confluent.io/platform/current/streams/concepts.html#processing-guarantees
Incomplete Implementation of Interfaces StateStore
For now, only KeyValueStore is supported (vs. e.g. WindowStore/SessionStore).
Also, not all methods have been implemented. Please check store types method support table above for more details.
Next Steps
Here are some of the tasks (high level) in the current backlog:
- Features
- Implement KIP-889: Versioned State Stores (coming soon with Kafka 3.5.0 release)
- Add a simple (optional) InMemory read cache -> Caffeine?
- Support
WindowStore/SessionStore
- Non-functional
- Benchmark
- Add metrics
- Ops
- GitHub actions to release + publish to maven central (snapshot / releases)
- Add Renovate
Interested to contribute? Please reach out!
Conclusion
It's been a fun journey so far, starting from an initial POC to a working library published to maven central - though still to be considered 'experimental', since it's not been production-tested yet.
The out-of-the-box state stores satisfy most requirements, no need to switch without necessity. Still, it's a usable piece of software that may fill a gap for specific requirements.
I'm looking forward to working on next steps such as benchmarking / load testing.
Feedback is very welcome, also, if you are planning to, or have decided to use the library in a project, please leave a comment below.
Footnotes
At the time of writing this blog post, the latest versions of relevant libs were
- Kafka / Streams API: 3.4.0
- Cassandra java-driver-core: 4.15.0
- kafka-streams-cassandra-state-store: 0.4.0